1. 背景
随着第四次工业革命浪潮的来临,一大批科技前沿技术逐渐兴起,人工智能、大数据、5G、物联网等技术不断渗透到各个领域,给各行各业带来巨大的改变。而随着技术的飞速发展,我们的衣食 住行正在悄然变化,在追求精神满足的情况下,人们正在不断完善自身的生活条件。房子是每个家庭的必需品,在购买房子时人们总是希望用较低的价格买到理想的房子,然而随着市场的变化,房价 时高时低,大众很难捕捉到很好的购房时机,因此房价预测就成为人们普遍关心的事情。很多学者在该领域进行了深入研究,有的通过引入数学模型,结合数据分析来预测房价的走势;有的通过市场分 析,结合国家宏观政策调控等,来预测房价的变化趋势。本文着重从数学模型来探究房价变化的因素,以1872年到2010年美国爱荷华州埃姆斯市的房价数据为着手点,通过全连接回归模型和平方差 损失函数来预测该市的房价。
2. 数据获取
本次房价数据集直接从kaggle网站下载1872年到2010年美国爱荷华州埃姆斯市的房价数据,链接地址:https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
部分样本如下表所示:
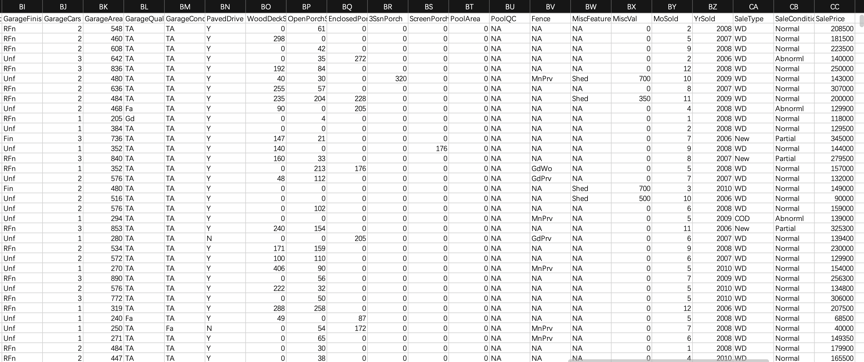
部分特征值如下表所示:
| Variable | Data Type | Comments |
|---|---|---|
| LotArea | 数值型 | 地皮面积 |
| GrLivArea | 数值型 | 生活面积 |
| TotalBsmtSF | 数值型 | 地下室总面积 |
| MiscVal | 数值型 | 其他资产 |
| GarageArea/GarageCars | 数值型 | 车库 |
| YearBuilt | 类别型 | 建造年份 |
| CentralAir | 类别型 | 中央空调 |
| OverallQual | 类别型 | 总体评价 |
| Neighborhood | 类别型 | 地段 |
数据集已下载到本地,训练集含1460个样本和80个特征和1个标签,测试集含1459个样本和80个特征。 代码如下:
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
# 读取训练集,1460个样本和80个特征和1个标签
train_data = pd.read_csv('./train.csv')
# 读取测试集,1459个样本和80个特征
test_data = pd.read_csv('./test.csv')
3. 数据预处理
对连续数值的特征做标准化:设该特征在整个数据集上的均值为μ,标准差为σ。那么,我们可以将该特征的每个值先减去μ再除以σ得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。
# 第一列是id,不需要,训练集最后一个是标签
all_features = pd.concat((train_data.iloc[:, 1:-1],test_data.iloc[:, 1:]))
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
# 标准化后,每个数值特征的均值变为0,所以可以直接用0来替换缺失值
all_features[numeric_features] = all_features[numeric_features].fillna(0)
接下来将离散数值转成指示特征,即离散的数值数字化
# dummy_na=True将缺失值也当作合法的特征值并为其创建指示特征
all_features = pd.get_dummies(all_features, dummy_na=True)
最后,通过values属性得到NumPy格式的数据,并转成Tensor方便后面的训练
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float)
train_labels = torch.tensor(train_data.SalePrice.values, dtype=torch.float).view(-1, 1)
4. 研究方法
在遇到使用机器学习难以解决的问题,深度学习可以较好拟合数据分布,例如图像识别,翻译等技术,现在大都是由深度学习完成的。本文将要使用全连接方式来对数据做回归训练,旨在探索深度学习的优势,全连接算法即使用神经元的连接并加上非线性激活函数来拟合最终数据。
4.1 算法思想
在深度学习中,每一个基本计算单位被称为神经元,在满足一定条件下,神经元将会把自身携带的信息传递给下游,这个过程叫做信息传输。在全连接中,神经元是按照分层的方式做信息传输的,首先从基本数据中将信息传递给第一层神经元,神经元经过信息加工处理后,结果将进入激活函数,然后从激活函数中得到最终信息值,这个信息值将会把结果发布到下一层的全部神经元中,下一层神经元再次处理并向下游传递信息。在训练过程中,采用反向传播的方式来对每一个神经元的参数做调整,经过训练后,将会得到多层的神经元参数,预测时便可以根据已经训练完成的神经元参数来对数据做分类或回归预测。
4.2 模型介绍
在本项目中,采用了两层隐藏层,一层输出层,维度分别为(特征维度,256),(256,128),(128,1),训练的损失函数采用的平方差函数,优化算法采用的是Adam。每层的丢弃率设置为0.4,激活函数为ReLU。
4.3 训练过程
使用平方损失函数和三层全连接层来训练模型。
# 平方损失函数
loss = torch.nn.MSELoss()
def get_net(feature_num):
num_inputs, num_outputs, num_hiddens_1, num_hiddens_2, drop_prob1, drop_prob2 = feature_num, 1, 256, 128, 0.4, 0.4
# 定义模型
net = nn.Sequential(
FlattenLayer(),
# 线性回归
nn.Linear(num_inputs, num_hiddens_1),
# 激活函数
nn.ReLU(),
# 丢弃法
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens_1, num_hiddens_2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens_2, num_outputs),
)
# 初始化权重和偏差
for p in net.parameters():
nn.init.normal_(p, mean=0, std=0.01)
return net
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x):
return x.view(x.shape[0], -1)
定义对数均方根误差公式:
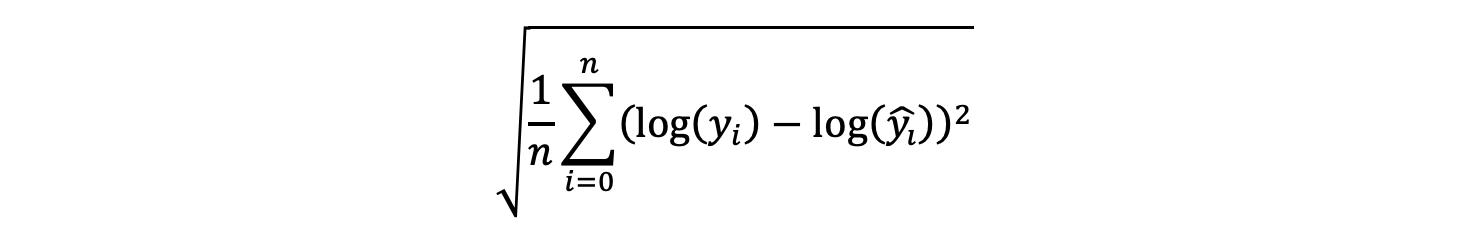
实现:
def log_rmse(net, features, labels):
with torch.no_grad():
clipped_preds = torch.max(net(features), torch.tensor(1.0))
rmse = torch.sqrt(loss(clipped_preds.log(), labels.log()))
return rmse.item()
定义训练函数:
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
optimizer = torch.optim.Adam(params=net.parameters(), lr=learning_rate, weight_decay=weight_decay)
net = net.float()
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(X.float()), y.float())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
使用K折交叉验证来选择模型设计并调节超参数,定义第i折交叉验证时所需要的训练和验证数据函数:
def k_fold(k, X_train, y_train, num_epochs,
learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net(X_train.shape[1])
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse',
range(1, num_epochs + 1), valid_ls,
['train', 'valid'])
print('fold %d: train rmse %f, valid rmse %f' % (i+1, train_ls[-1], valid_ls[-1]))
return train_l_sum / k, valid_l_sum / k
使用pyplot作为画图工具
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
plt.semilogy(x2_vals, y2_vals, linestyle=':')
plt.legend(legend)
K折交叉验证调节超参数
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.02, 1, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print('%d-fold validation: avg train rmse %f, avg valid rmse %f' % (k, train_l, valid_l))
打印结果:
fold 1: train rmse 0.145836, valid rmse 0.179289
fold 2: train rmse 0.146976, valid rmse 0.201118
fold 3: train rmse 0.142592, valid rmse 0.182664
fold 4: train rmse 0.146487, valid rmse 0.179900
fold 5: train rmse 0.142367, valid rmse 0.194614
5-fold validation: avg train rmse 0.144852, avg valid rmse 0.187517
RMSE:
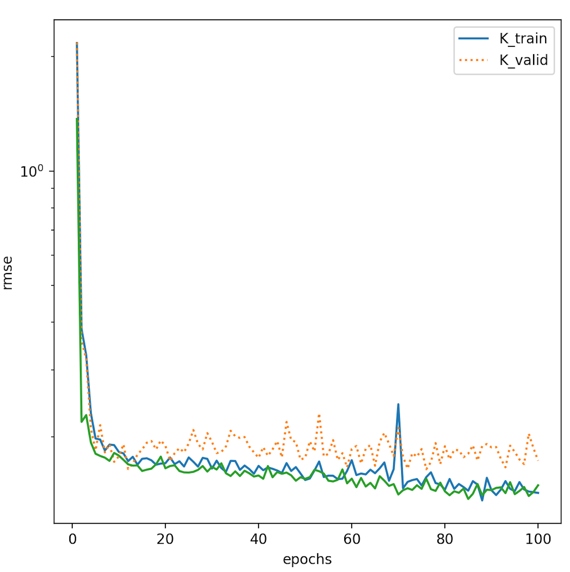
定义训练和预测函数
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, wd, batch_size):
net = get_net(train_features.shape[1])
train_ls, _ = train(net, train_features, train_labels, None, None, num_epochs, lr, wd, batch_size)
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse')
print('train rmse %f' % train_ls[-1])
pred = net(test_features).detach().numpy() # detach() 切断向前传播,requires_grad=false
test_data['SalePrice'] = pd.Series(pred.reshape(1, -1)[0])
pred = pd.concat([test_data["Id"], test_data['SalePrice']], axis=1)
# 预测结果保存带本地
pred.to_csv('./pred.csv', index=False)
训练rmse为0.140844
部分预测房价结果如下:
Id,SalePrice
1461,137415.67
1462,132947.58
1463,171980.8
1464,190884.72
1465,200018.27
1466,154527.02
1467,188457.05
1468,177869.64
1469,194025.77
1470,114387.81
- 总结
国内经济水平不断提高,各个城市基础设施不断完善,近年来房价迅速增长。通过结合梯度下降算法的线性回归分析,建立一个房价的预测机制,以回归结果为依据,从而对房价有一个较为准确的预测,进而为个人和城市的发展提供角度和方法。在模型的实现中遇到了很多的困难,数据源的收集、数据缺失值处理、回归分析以及模型构建等,通过翻阅了大量的相关书籍以及技术博客完成这些工作。但是基于梯度下降算法的房价回归与预测模型仍然还有需要改进和完善的地方,如何构建一个精确度更高的模型和加快算法速度依旧是一个挑战,希望在后续的学习研究中能够利用神经网络相关的知识构建一个精确率较高、泛化能力较好的模型。
一些题外话:
挺长时间没有更新博客了,去年下半年太忙了,一方面是工作的事,另一个方面是学校的事(花了两年时间考上某211非全研究生,计科专业),学校把大部分的课集中在研一上半学期,所以平时工作加班加点,周末时间上课,准备各种结课报告和考试,直到学校放假,才闲暇起来,不过,这半学期,认识了很多老师和新同学,都比较厉害,我也接触到人工智能相关领域,后面我会根据自己平时所学和实践,整理到我的博客中。